Ligipääs Rahvusraamatukogu ajalehtede ja ajakirjade tekstikogule
Kirjeldus
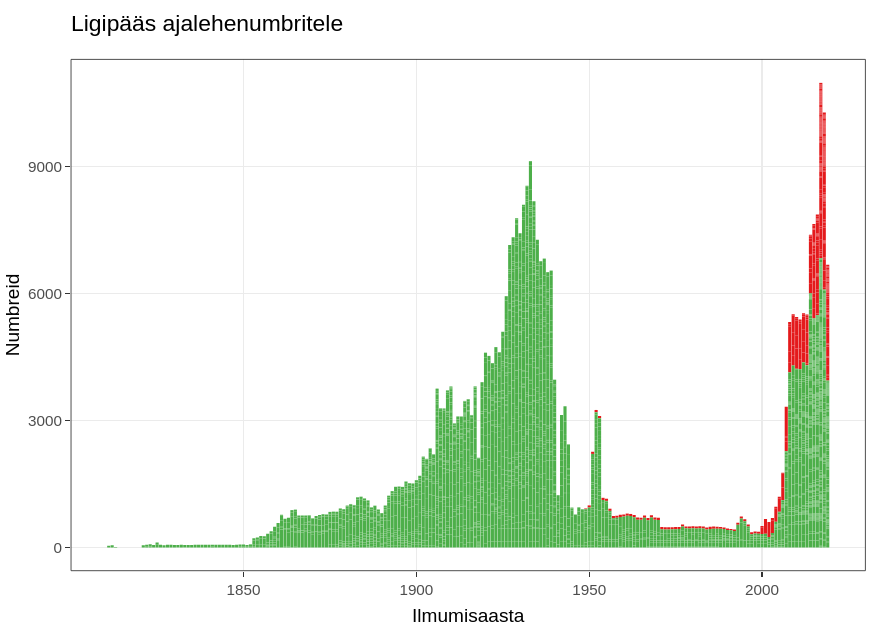
Digiteeritud Eesti Artiklid on otsitavad veebiliidese kaudu https://dea.digar.ee/ ja ligipääsetav ka andmestikuna. Ülevaade andmestikust on eraldi lehel.
Andmetele ligipääs käib pilves JupyterHub keskkonna kaudu, kus saab jooksutada koodi ja kirjutada Jupyter Notebook-e, kasutades R-i ja Pythonit.
JupyterHub keskkonnas on ligipääs täistekstidele ja metaandmetele, võimalus kirjutada oma analüüs ja laadida alla oma leiud. Andmed on avatud kõigile kasutamiseks.
Kuidas alustada
Keskkonna kasutamiseks on vajalik teha endale kasutajanimi ETAISi. Kasutajanime saamiseks pöörduge aadressile data@digar.ee.
Andmestikule mugavaks ligipääsuks on loodud R pakett digar.txts, mille kaudu saab eraldada tervikkollektsioonist osa ning teha otsinguid täistekstil.
Andmete töötlusel on võimalik kasutada enda koodi, toetuda mõnele näidisanalüüsile või võtta välja otsingu tulemused tabeli kujul.
Lühidalt
- Mine veebilehele https://jupyter.hpc.ut.ee/ ja logi sisse (kasutajanime saab data@digar.ee).
- Vali vaikeväärtus (1 CPU core, 8 GB memory, 6h timelimit)
- Loo uus Notebook R-i tuumaga.
- Kasuta koodi koodi kasutamise sektsioonist
- Lae üles näited algajale: eesti keeles või inglise keeles
- Vaata näidisanalüüse: hobu, elekter, aur 20. saj algul (.html, .ipynb, .Rmd)
- Töötoad: Nelijärve 5. nov 2020, Kevad 2020 eestikeelne lühikursus tekstitöötlusest R-is
Märkusi
- Tartu Ülikooli võrgus on ka ligipääs võimalik RStudio kaudu https://rstudio.hpc.ut.ee/. Tulevikus peaks saama RStudio kaudu ligi ka iga kasutaja.
JupyterHub-iga alustamine
- Mine veebilehele https://jupyter.hpc.ut.ee/ ja logi sisse.
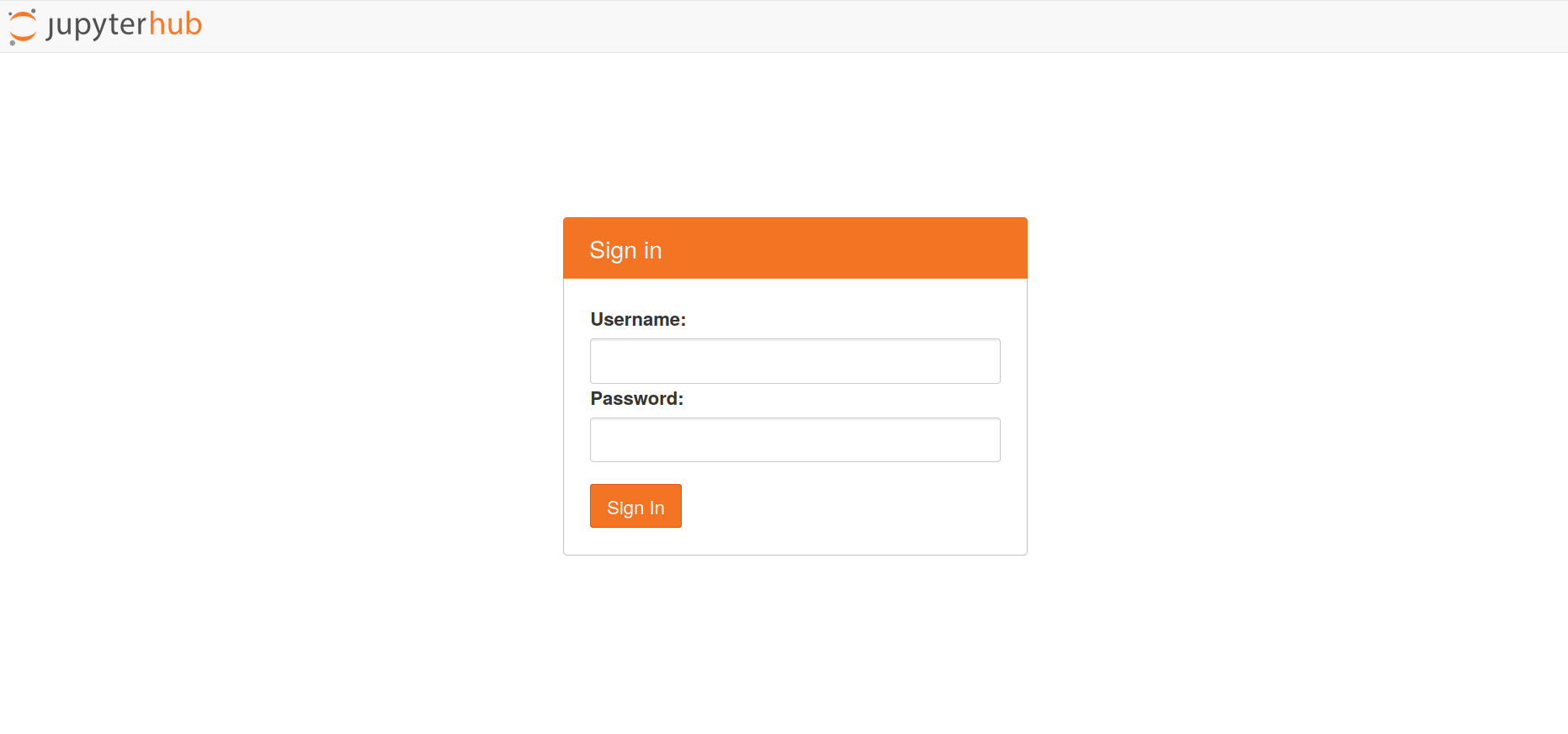
- Vali esimene pakutud variant (1 CPU core, 8GB memory, 6h timelimit). See avab andmetöötluse akna kuueks tunniks. Kõik teie failid säilitatakse teie kasutajanime juures püsivalt.
- Oota kuni masin käivitub. See võib võtta mõne minuti olenevalt järjekorrast. Mõnikord on abi ka lehe värskendamisest (refresh).
- Õnnestunud käivitamise korral näete midagi sellist. Vasakul on failid ja sinna saab neid üles laadida (üles noolega nupp või tiri failid sellesse kasti) või luua uusi faile (+ märk). Paremal koodiaknad, märkmikud ja materjalid. Näites on just avatud uus Jupyteri Notebook.
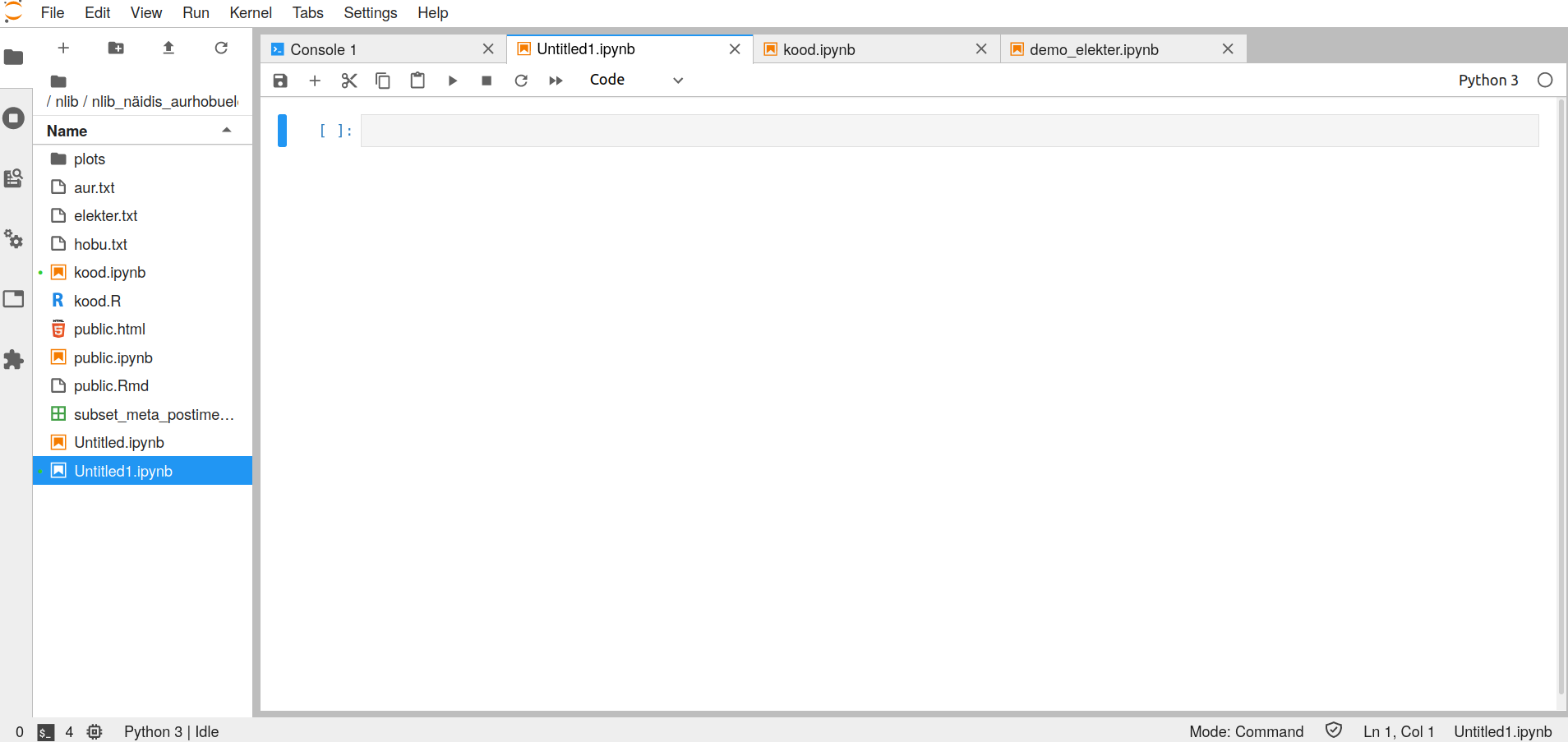
- Notebook-is saab kasutada Pythonit või R-i. Märkmikku kasutades tuleb valida neil õige arvutussisu (kernel). Seda saab teha dokumenti luues või juba loodud dokumendis Kernel -> Change Kernel või paremal ülal vajutada kerneli nimel. Siis avaneb järgmine vaade.
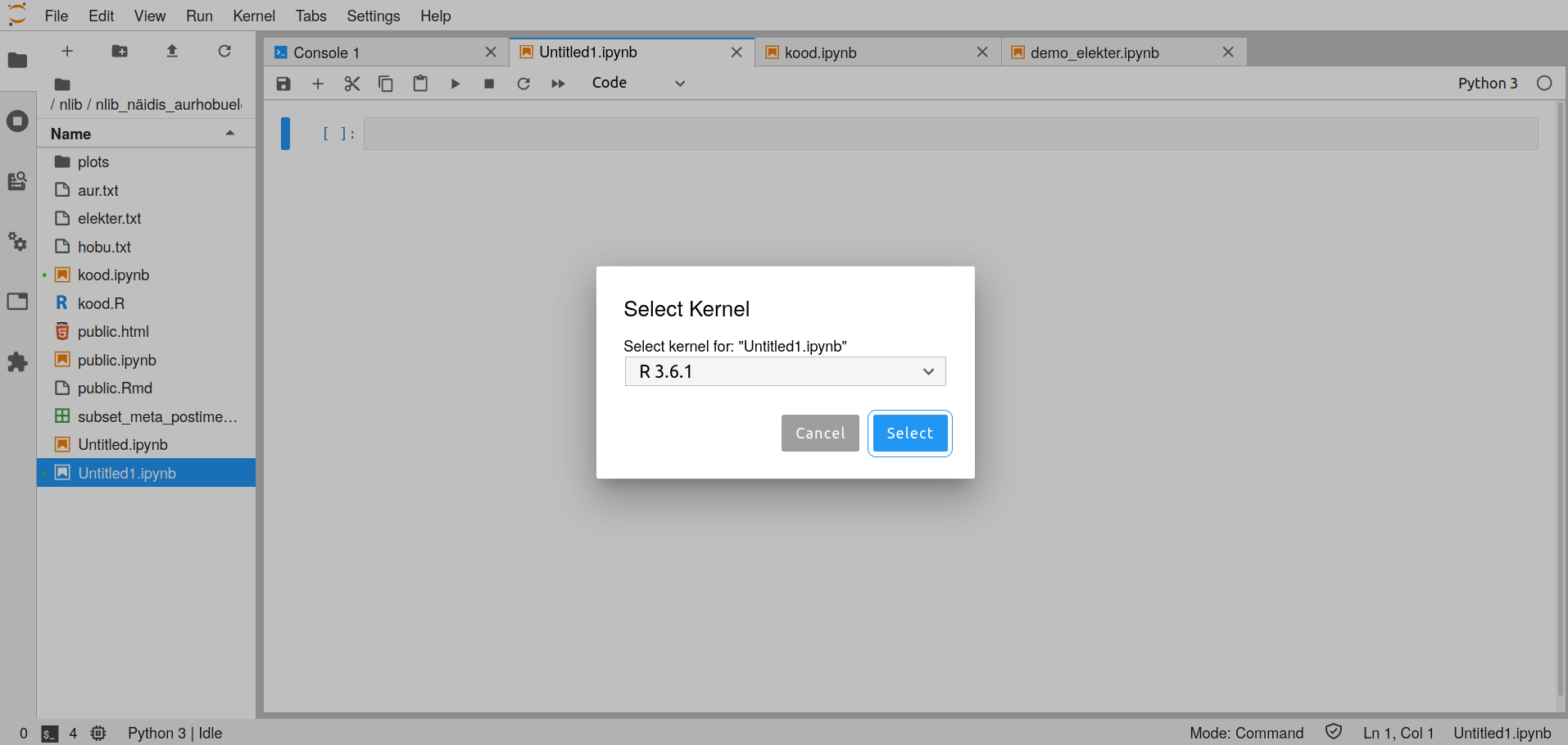
- Ligipääs tekstidele on praegu R-i kaudu. Soovitan on teha esialgne päring nende vahenditega ja kasutada pärast seda endale meelepäraseid vahendeid.
Pakett
Ligipääs failidele on toetatud R-i paketi poolt digar.txts, mis paari lihtsa käsuga 1) annab ülevaate andmekogust koos seostega failidele, 2) võimaldab moodustada andmestikust vajalikke alamhulki, 3) võimaldab teha tekstiotsingut ja 4) võimaldab otsingu tulemustes võtta välja leidude vahetu konteksti. Otsingu tulemused võib edasi salvestada ka tabelisse ja töötada juba väiksema koguga edasi mujal.
Need käsud on: - get_digar_overvew() - loeb sisse ülevaate tervst kollekstioonist (numbrite tasandil) - get_subset_meta() - loeb sisse alamhulga metainformatsiooni (artikli tasandil) - do_subset_search() - teostab alamhulgas otsingu ja salvestab tulemused faili (artiklite kaupa) - get_concordances() - leiab otsingutulemustest konkordantsid (s.t. otsingusõna ja selle vahetu konteksti)
Vahepealseks töötluseks sobivad igasugu R-i paketid ja käsud. Töötluseks Pythonis tuleks andmed enne kokku koguda ja teha uus Pythoni märkmik.
Koodi kasutamine
- Kõigepealt tuleb installida digar.txts pakett
#Kuna JupyterHub ei anna kirjutamisõigust kõigile failidele, teeme kõigepealt kohaliku kataloogi, kuhu pakett installida.
dir.create("R_pckg")
remotes::install_github("peeter-t2/digar.txts",lib="~/R_pckg/",upgrade="never")- Käivitage installitud pakett
library(digar.txts,lib.loc="~/R_pckg/")- Kasuta get_digar_overview() käsku andmestiku sisust ülevaate saamiseks
all_issues <- get_digar_overview()- Ehita oma valim andmetest kasutades R-i käske. Siin on tidyverse stiilis näide.
library(tidyverse)
subset <- all_issues %>%
filter(DocumentType=="NEWSPAPER") %>%
filter(year>1880&year<1940) %>%
filter(keyid=="postimeesew")
- Hangi alamhulga metainformatsioon (iga artikli kohta) käsuga get_subset_meta(). Juhul kui me kasutame seda infot korduvalt on soovitav metaandmestik salvestada faili. Täismetaandmestikuks on meil vaja ka varem võetud ülevaadet all_issues.
subset_meta <- get_subset_meta(subset)
#potentially write to file, for easier access if returning to it
#readr::write_tsv(subset_meta,"subset_meta_postimeesew1.tsv")
#subset_meta <- readr::read_tsv("subset_meta_postimeesew1.tsv")- Teeme märksõnaotsingu käsuga do_subset_search(). See salvestab otsingu tulemused faili artiklite kaupa. Käsk vaikimisi eirab suur ja väiketähti.
do_subset_search(searchterm="lurich", searchfile="lurich1.txt",subset)- Loe sisse otsingu tulemused failist. Edasi saab kasutada R-i tööriistu töötluseks. Kasulik on nimetada otsingu tulbad ümber id-ks ja txt-ks.
texts <- fread("lurich1.txt",header=F)[,.(id=V1,txt=V2)]- Hangi otsingusõnad lähemas kontekstis ehk konkordantsd käsuga get_concordances()
concs <- get_concordances(searchterm="[Ll]urich",texts=texts,before=30,after=30,txt="txt",id="id")Märkus: et kasutada ctrl+shift+m klahve %>% toru kirjutamiseks Jupyteris, tuleb lisada väike koodijupp. Selleks mine Settings -> Advanced Settings Editor… -> Keyboard Shortcuts vasakul pool User Preferences kastis ja lisa sinna järgnev kood. ctrl+shift+m peaks nüüd töötama.
{
"shortcuts": [
{
"command": "notebook:replace-selection",
"selector": ".jp-Notebook",
"keys": ["Ctrl Shift M"],
"args": {"text": '%>% '}
}
]
}Lihtsamad R-i käsud
- <- - salvesta väärtused
- %>% - ‘toru’ mis suunab väärtusi edasi
- filter() - vii oma andmed läbi filtri (säilitades sobivad väärtused)
- count() - loenda väärtuste esinemisi
- mutate() - loo uus tulp (saab kasutada nt n(), row_number(), min(), max() uute väärtuste arvutamisel)
- head(n) - võta esimesed n rida